禁用词处理 在测试过程中,发现经常在对话中出现「……」的情况,经过分析剧本中有至少2K个类似回复。尽管此类回复配合CG图像能够从侧面表现人物心态的作用,但在AIGC工作中需要正面回答的回复。因此需要将剧本中相关字符去除,类似的还有***符号等。
……
使用sed命令进行文本文件预处理,并将结果放置于pt_txt文件夹下,用于预训练。此外,sft微调脚本也需要重新执行。
1 2 3 4 5 6 sed '/「………」/d' CLANNAD.txt > CLANNAD_NODOT.txt_1 sed '/「……」/d' CLANNAD_NODOT.txt_1 > CLANNAD_NODOT.txt_2 sed '/「…」/d' CLANNAD_NODOT.txt_2 > CLANNAD_NODOT.txt sed '/………/d' CLANNAD_NODOT.txt > CLANNAD_NODOT.txt_3 sed '/\*\*\*\*\*/d' CLANNAD_NODOT.txt_3 > CLANNAD_NODOT.txt sed '/嗯…/d' CLANNAD_NODOT.txt > CLANNAD_NODOT.txt_e
分割微调数据 书接上回,由于训练出来的大模型回答效果过拟合。
随机分割数据集,并将数据集和测试集分为7:3。调整原有代码如下,将不同角色之间的对话进行聚类、随机分割。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public BuildFinetuneFile map () for (FinetuneWithCharacter finetuneWithCharacter : finetuneWithCharacters) { String characterKey = finetuneWithCharacter.getInputCharactor() + "_" + finetuneWithCharacter.getOutputCharactor(); List<Finetune> finetunes = finetuneMap.getOrDefault(characterKey, new ArrayList<>()); finetunes.add(finetuneWithCharacter.getFinetune()); finetuneMap.put(characterKey, finetunes); } return this ; } public void split (List<Finetune> dataset, List<Finetune> validator) for (String character : finetuneMap.keySet()) { List<Finetune> list = finetuneMap.get(character); Collections.shuffle(list); int splitPoint = (int ) (list.size() * 0.7 ); dataset.addAll(list.subList(0 , splitPoint)); validator.addAll(list.subList(splitPoint, list.size())); } }
启动脚本更新如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws IOException Parser parser = new Parser("CLANNAD.txt" ); List<Finetune> dataset = new ArrayList<>(); List<Finetune> validator = new ArrayList<>(); new BuildFinetuneFile(parser.parseLines()).prepare().map().split(dataset, validator); BufferedWriter finetuneOut = new BufferedWriter(new FileWriter("finetune_json/CLANNAD_LLaMA_finetune.json" )); BufferedWriter validatorOut = new BufferedWriter(new FileWriter("validator_json/CLANNAD_LLaMA_validator.json" )); finetuneOut.write(new Gson().toJson(dataset)); validatorOut.write(new Gson().toJson(validator)); finetuneOut.close(); validatorOut.close(); }
修改预训练、精调配置 pt预训练配置 1 2 3 4 5 6 7 8 pretrained_model=/mnt/workspace/chinese-alpaca-2-7b chinese_tokenizer_path=/mnt/workspace/chinese-alpaca-2-7b dataset_dir=/mnt/workspace/CLANNAD_LLaMA/pt_txt data_cache=/mnt/workspace/cache per_device_train_batch_size=1 gradient_accumulation_steps=8 block_size=512 output_dir=/mnt/workspace/CLANNAD_LLaMA_model_pt
–num_train_epochs配置为30,让模型充分学习。
sft精调配置 第一轮sft
1 2 3 4 5 6 7 8 9 pretrained_model=/mnt/workspace/CLANNAD_LLaMA_model_pt_merged chinese_tokenizer_path=/mnt/workspace/CLANNAD_LLaMA_model_pt_merged dataset_dir=/mnt/workspace/CLANNAD_LLaMA/finetune_json per_device_train_batch_size=1 per_device_eval_batch_size=1 gradient_accumulation_steps=8 max_seq_length=512 output_dir=/mnt/workspace/CLANNAD_LLaMA_model_sft validation_file=/mnt/workspace/CLANNAD_LLaMA/validator_json/CLANNAD_LLaMA_validator.json
第二轮sft
1 2 3 4 5 6 7 8 9 pretrained_model=/mnt/workspace/CLANNAD_LLaMA_model_sft_merged chinese_tokenizer_path=/mnt/workspace/CLANNAD_LLaMA_model_sft_merged dataset_dir=/mnt/workspace/CLANNAD_LLaMA/finetune_json per_device_train_batch_size=1 per_device_eval_batch_size=1 gradient_accumulation_steps=8 max_seq_length=512 output_dir=/mnt/workspace/CLANNAD_LLaMA_model_sft_2 validation_file=/mnt/workspace/CLANNAD_LLaMA/validator_json/CLANNAD_LLaMA_validator.json
执行脚本时报OOM(16G V100),将–load_in_kbits改为4。
此外–save_total_limit参数改为1,防止磁盘占用过大导致任务终止。
–num_train_epochs提升到10,多训练几轮。
合并参数 合并预训练参数
1 2 3 4 5 cd /mnt/workspace/Chinese-LLaMA-Alpaca-2 && python scripts/merge_llama2_with_chinese_lora_low_mem.py \ --base_model /mnt/workspace/chinese-alpaca-2-7b \ --lora_model /mnt/workspace/CLANNAD_LLaMA_model_pt \ --output_type huggingface \ --output_dir /mnt/workspace/CLANNAD_LLaMA_model_pt_merged
合并精调参数
1 2 3 4 5 cd /mnt/workspace/Chinese-LLaMA-Alpaca-2 && python scripts/merge_llama2_with_chinese_lora_low_mem.py \ --base_model /mnt/workspace/CLANNAD_LLaMA_model_pt_merged \ --lora_model /mnt/workspace/CLANNAD_LLaMA_model_sft/checkpoint-5000/sft_lora_model \ --output_type huggingface \ --output_dir /mnt/workspace/CLANNAD_LLaMA_model_sft_merged
测试效果 角色能够引述其他角色的对话。
角色能够引述其他角色的对话
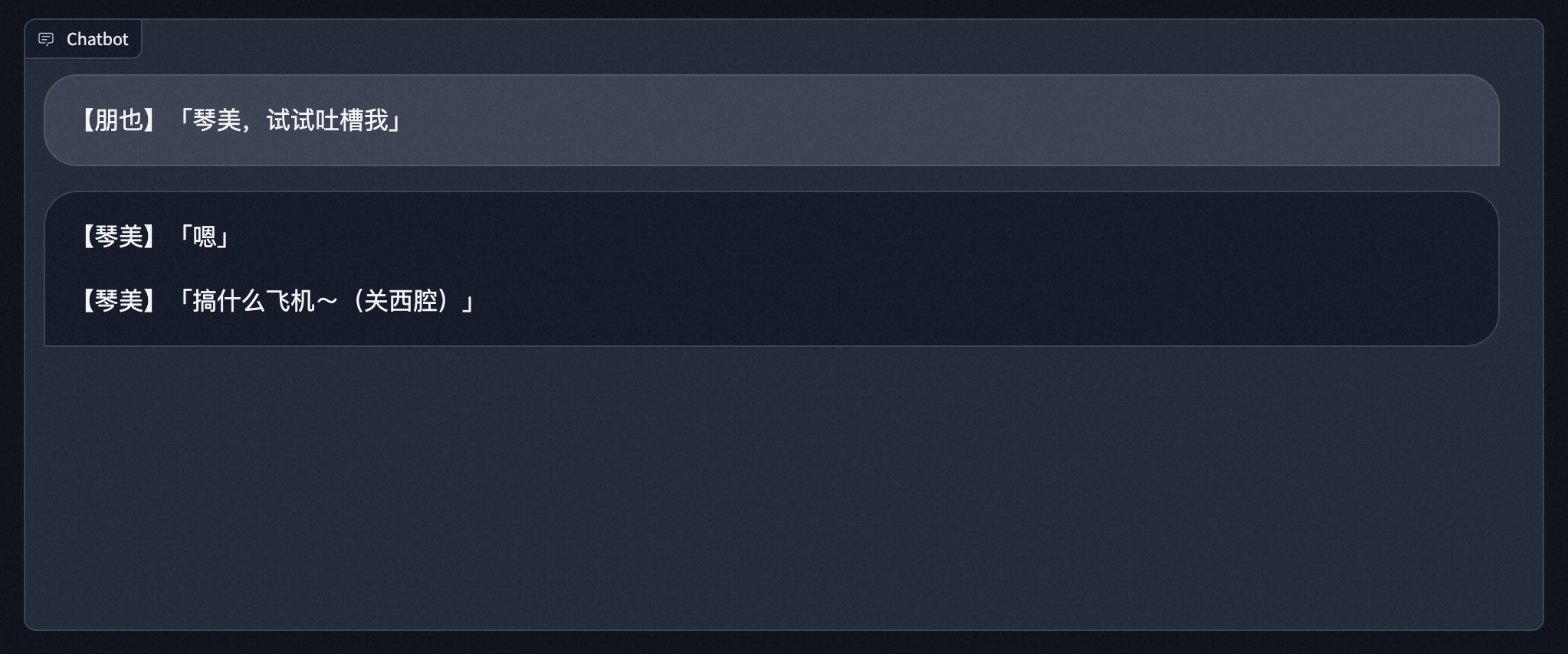
琴美终于会吐槽了,还很专业!
琴美终于会吐槽了
符合角色基础属性,而且称呼正确。
符合角色属性
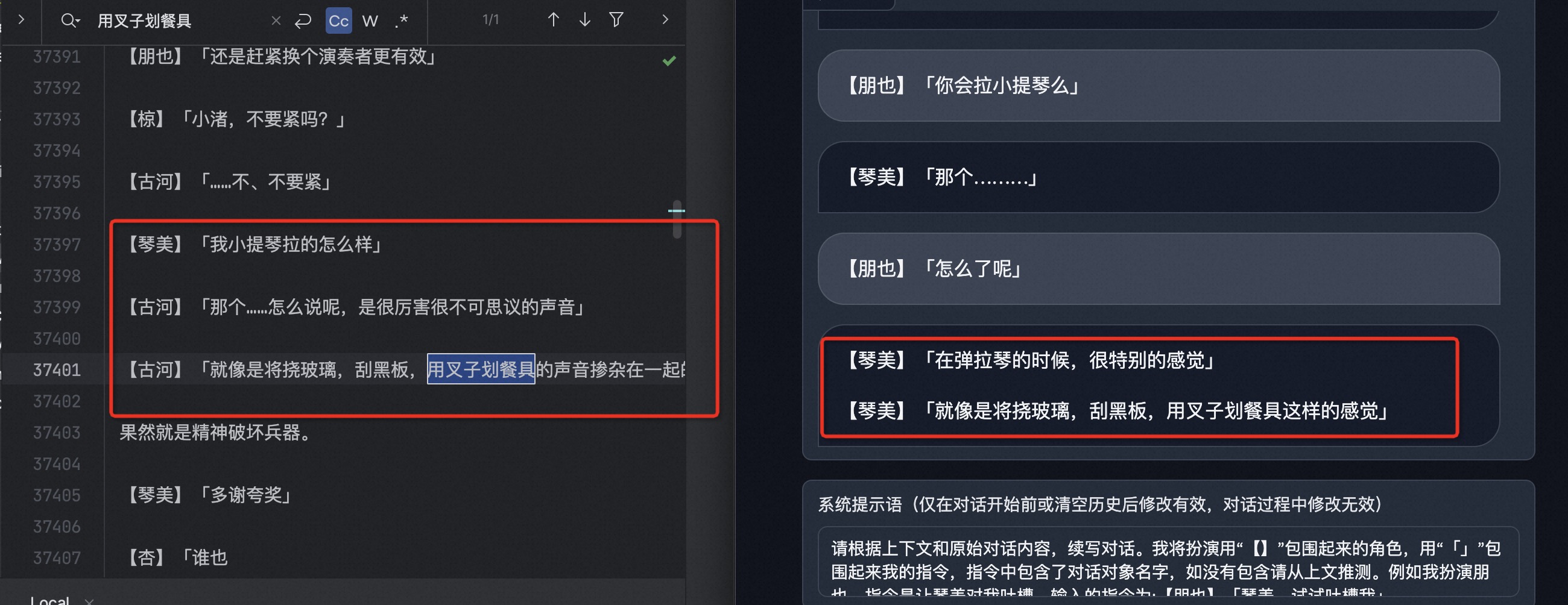
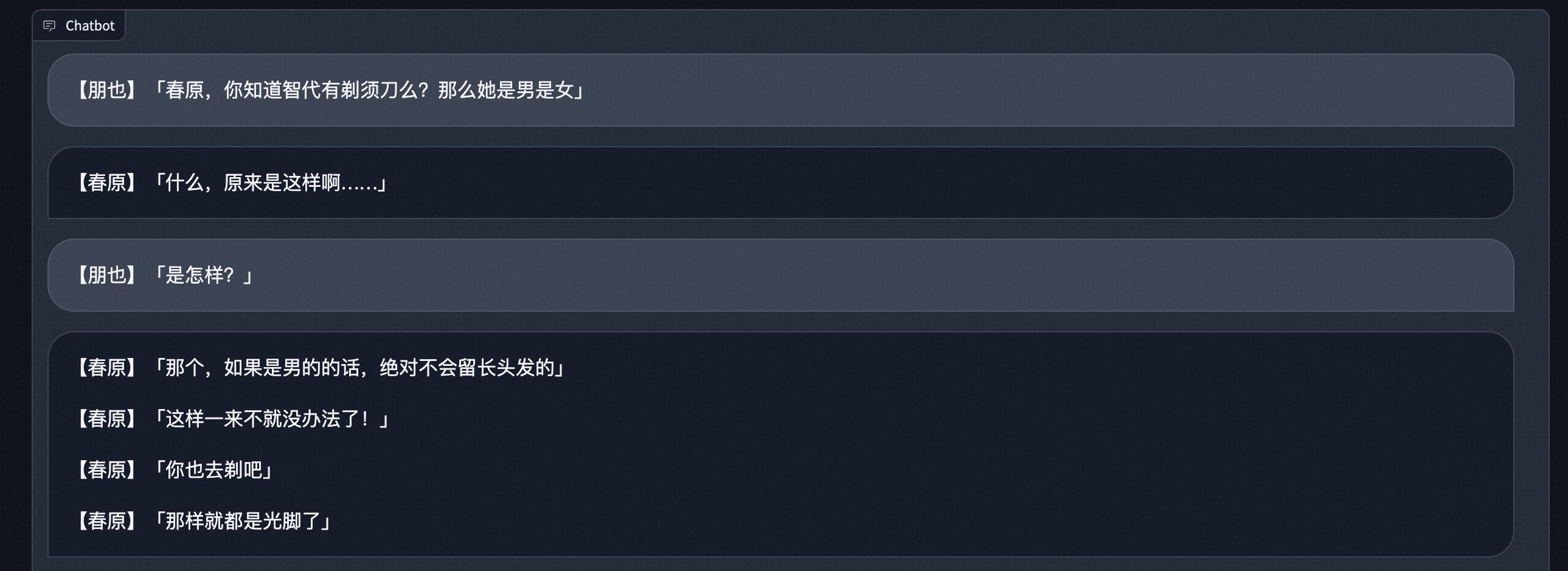
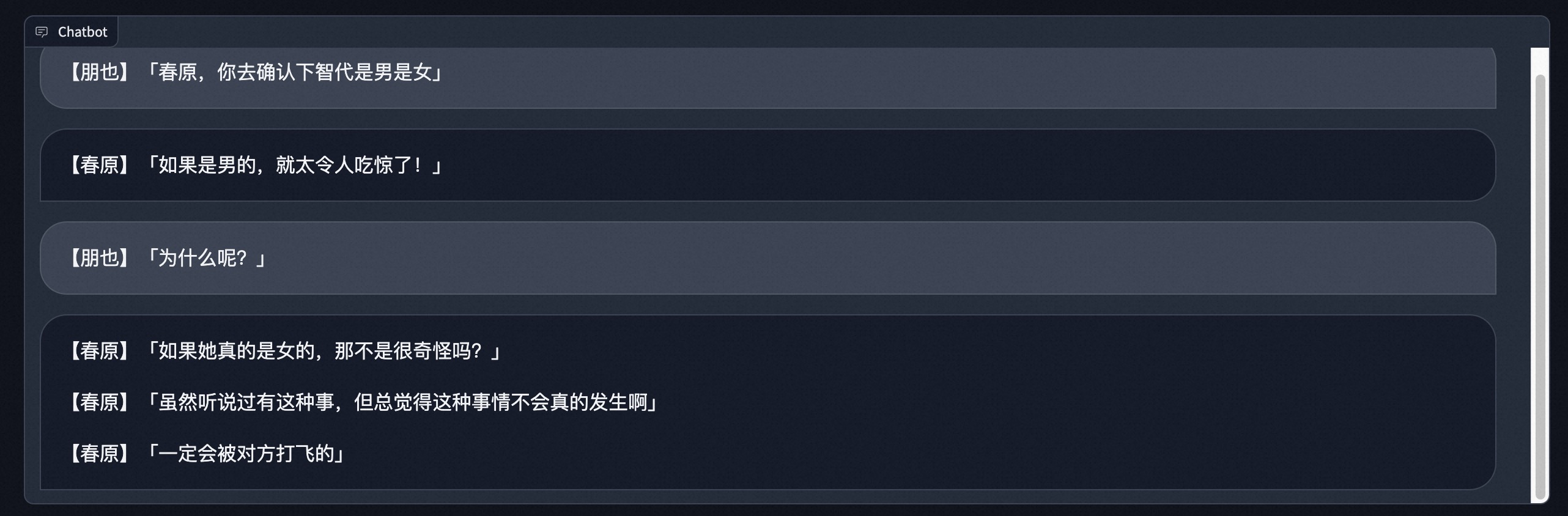
模型拥有了推理能力,和角色的性格也比较拟合。(按照原剧本,春原为了确认智代是男是女,用对方有没有剃须刀的欠揍方法询问。)
模型对话推理
春原经过无数次挨揍,终于长记性了。
的确会被揍飞