准备微调
书接上回,已经把CLANNAD剧本进行解析,并处理为LLaMA能够微调的JSON文件,接下来就开始实际操作LLaMA的微调工作。
由于微调需要的资源比较多,而且可能要花好几个小时,不可避免退出Colab标签页,因此化身氪金玩家转战AutoDL。
转战AutoDL的部分原因也有训练速度要比Colab快一些,5月份时曾经训练个狗脸识别模型,AutoDL的训练速度要完爆Colab。果然是人民币的力量!
微调之前还是需要把预训练模型下载下来,又优于下载模型需要磁盘空间比较大、消耗时间较长,因此请扩容数据盘并使用”无卡模式“开机,要么GPU空跑费用真烧不起。
下模型的时候,看看官方微调文档,熟悉一下微调流程。
这感人速度,陷入沉思,要么打几把CSGO吧……
过于感人/抓狂的下载速度
执行以下命令:
打开AutoDL学术加速
1 | import subprocess |
clone一堆库,pip安装依赖
1 | git clone https://github.com/SUTFutureCoder/CLANNAD_LLaMA.git |
安装git-lfs,因为预训练模型文件比较大
1 | wget https://github.com/git-lfs/git-lfs/releases/download/v3.0.1/git-lfs-linux-amd64-v3.0.1.tar.gz |
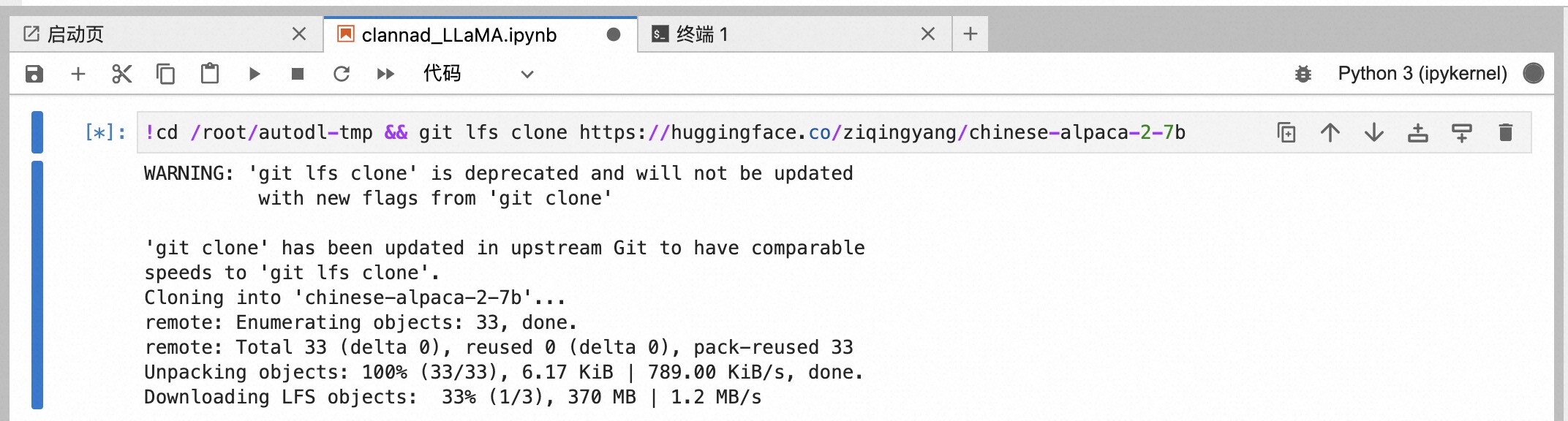
下载预训练模型(非常非常慢,1.2m/s大概2h+)
1 | cd /root/autodl-tmp && git lfs clone https://huggingface.co/ziqingyang/chinese-alpaca-2-7b |
使用gradio试试预训练模型效果(注意,如果不学术加速,则不会提供gradio公网反向代理链接)
1 | cd /root/autodl-tmp && python ../Chinese-LLaMA-Alpaca-2/scripts/inference/gradio_demo.py --base_model chinese-alpaca-2-7b --load_in_8bit |
按照精调文档,配置bash脚本,其他参数暂时不动。
1 | pretrained_model=/root/autodl-tmp/chinese-alpaca-2-7b |
执行预训练脚本
1 | cd /root/Chinese-LLaMA-Alpaca-2/scripts/training && bash run_pt.sh |
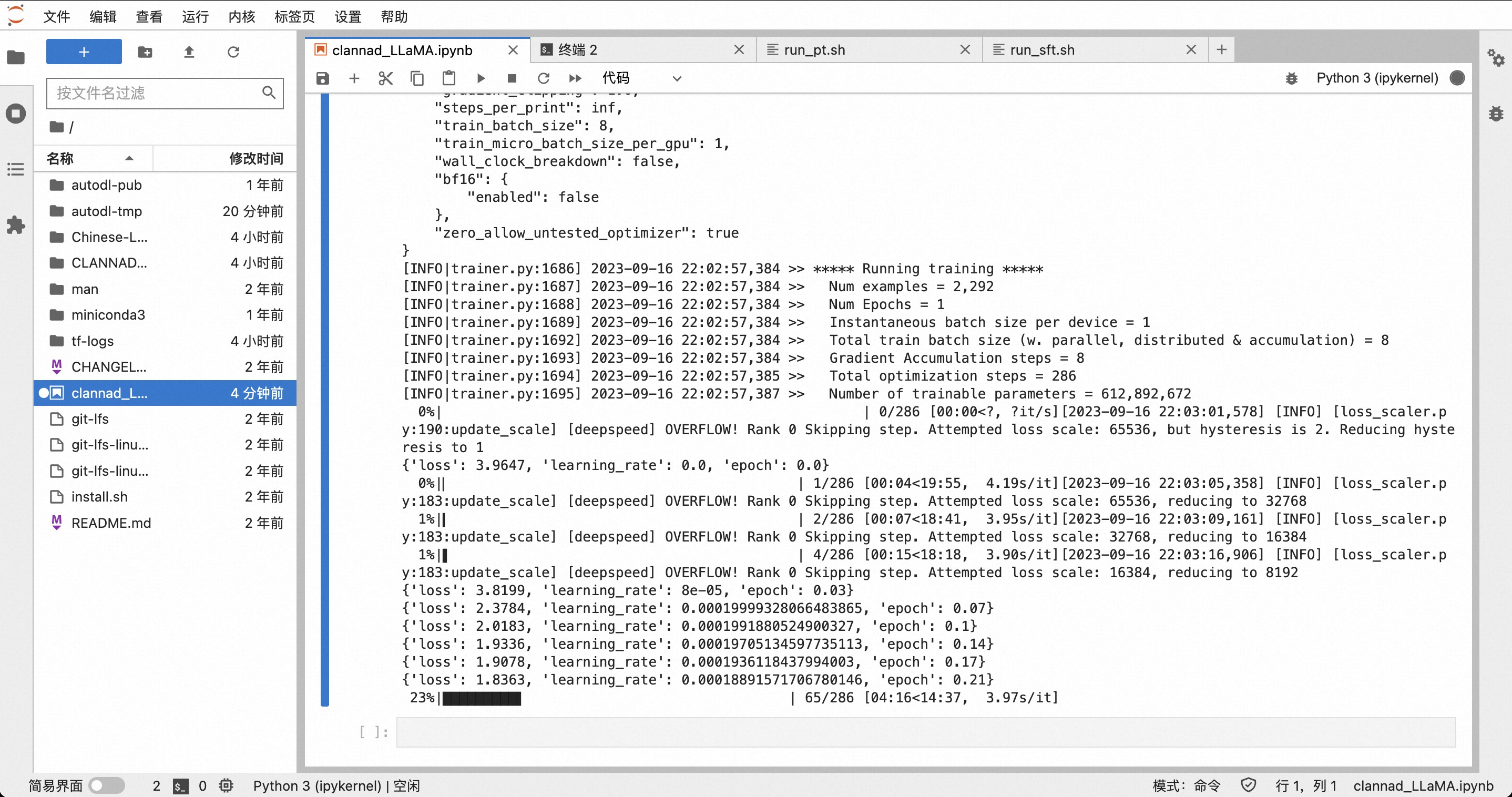
跑起来了,好耶ヾ(✿゚▽゚)ノ
预训练txt会包含场景和上下文信息
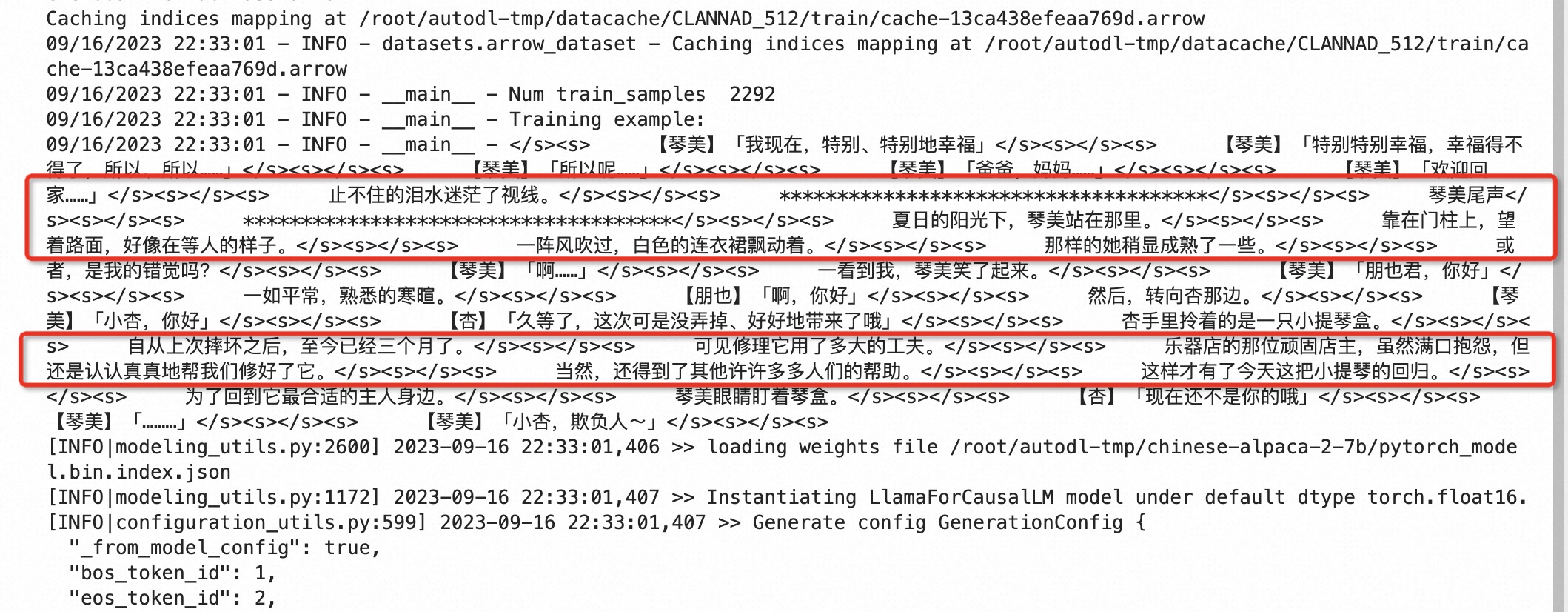
需要把json文件独立一个文件夹
合并参数
1 | cd /root/Chinese-LLaMA-Alpaca-2 && python scripts/merge_llama2_with_chinese_lora_low_mem.py \ |
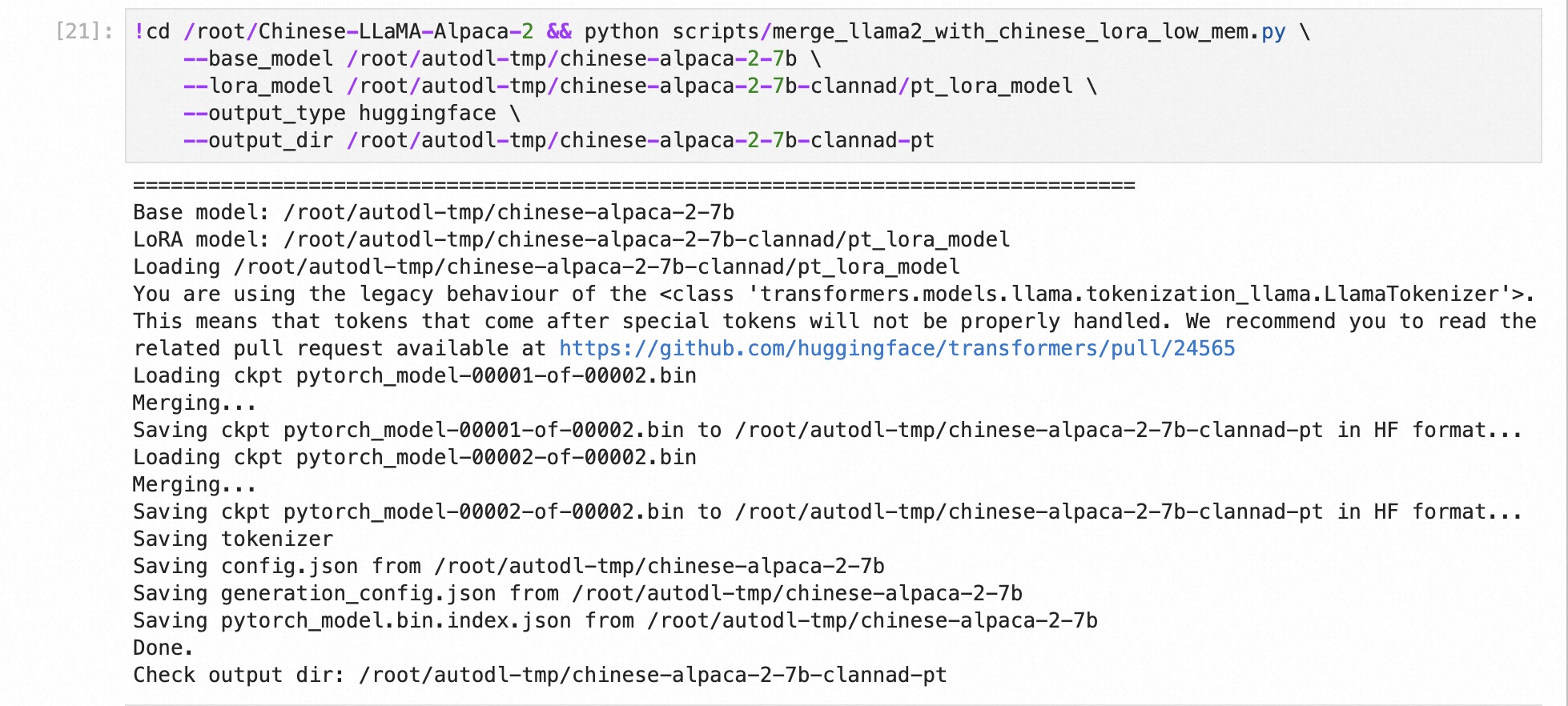
合并参数
然后再微调
1 | pretrained_model=/root/autodl-tmp/chinese-alpaca-2-7b-clannad-pt |
1 | cd /root/Chinese-LLaMA-Alpaca-2/scripts/training && bash run_sft.sh |
合并参数
1 | cd /root/Chinese-LLaMA-Alpaca-2 && python scripts/merge_llama2_with_chinese_lora_low_mem.py \ |

各个训练步骤产出的模型或参数文件
使用gradio打开在线交互界面
1 | cd /root/autodl-tmp && python ../Chinese-LLaMA-Alpaca-2/scripts/inference/gradio_demo.py --base_model chinese-alpaca-2-7b --load_in_8bit |
构建prompt
1 | 请根据上下文和原始对话内容,续写对话。我将扮演用“【】”包围起来的角色,用“「」”包围起来我的指令,指令中包含了对话对象名字,如没有包含请从上文推测。例如我扮演朋也,指令是让琴美对我吐槽,输入的指令为:【朋也】「琴美,试试吐槽我」 |
试一试模型能否理解上下文
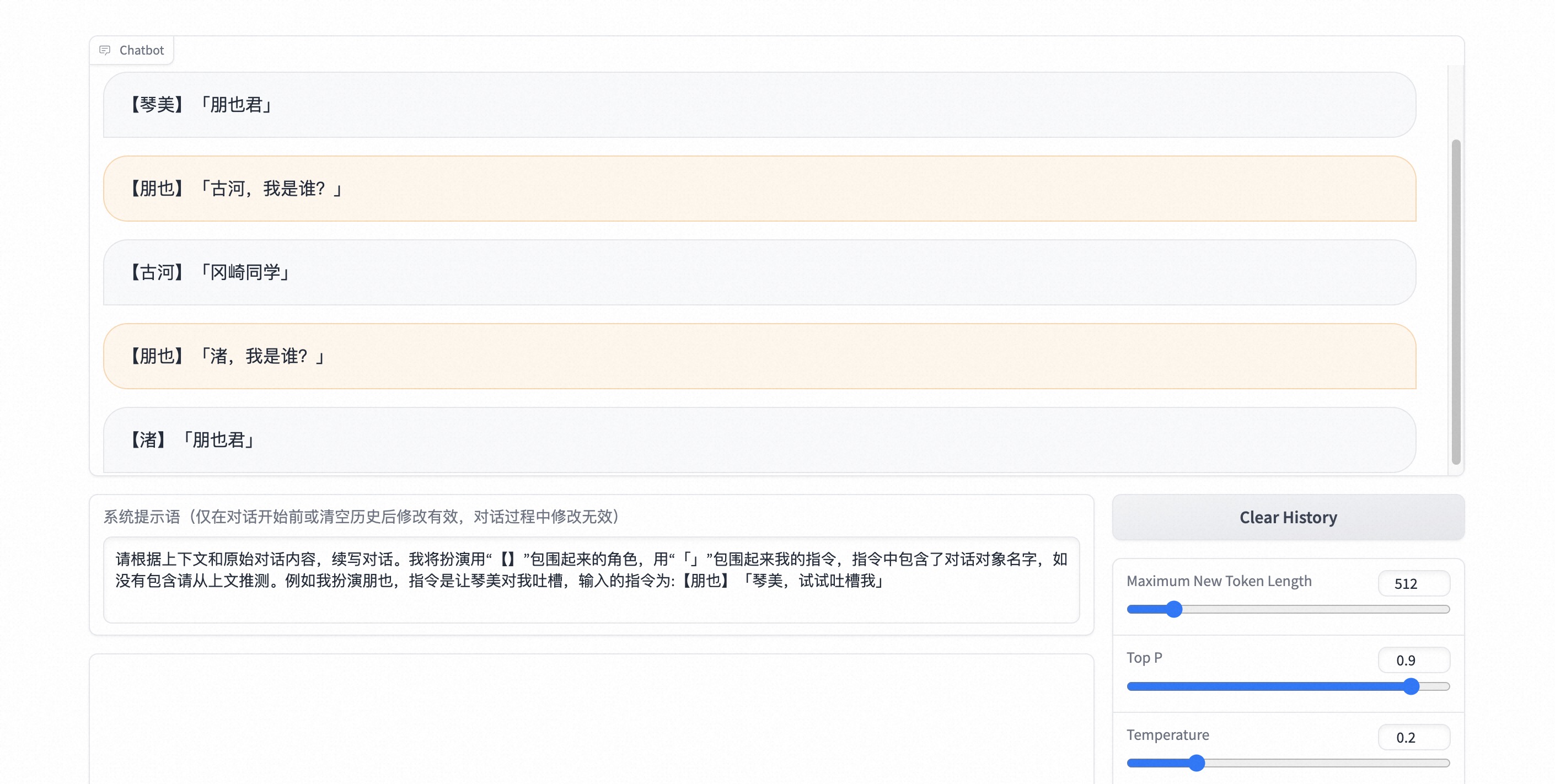
不同角色对主角的不同称呼(与关系相关)
可以认为已经成功训练出来了一个对话大模型,虽然跟标题写的“续写CLANNAD”有些跑偏,但至少完成了一整套大模型的训练流程。
但实际效果还是不太行,还是无法让目标角色通过原文上半句接下半句,我认为是因为训练集和验证集相同导致过拟合的原因。
接下来准备将每个角色的后30%发言作为验证集进行训练,所有代码和notebook我继续放到这里。

