准备微调数据 今天计划完成如下目标:
读取文件
统计数据
清洗数据
构造微调JSON
尝试微调LLaMA大模型
代码和运行结果放在Github中
解析角色发言 由于Java是我每天吃饭用的工具,虽然Python很香,但我选Java。毕竟准备微调数据JSON是一次性工作,不参与模型训练中,所以直接用比较顺手的工具解析并构造即可。
首先定义两个核心数据类,第一个是角色发言,每个对象存储角色名称以及对应的发言或思考。
1 2 3 4 5 @Data public class CharacterQuote String name; String quote; }
第二个是用于微调大模型的JSON基础对象,需要符合Stanford Alpaca格式。
1 2 3 4 5 6 @Data class FinetuneJson String instruction; String input; String output; }
解析第一步肯定是读取文件、按行解析、去掉前后空格、尝试输出。感谢Galgame剧本格式,基本都在一行并使用“【XXX】”来标记是谁说的。
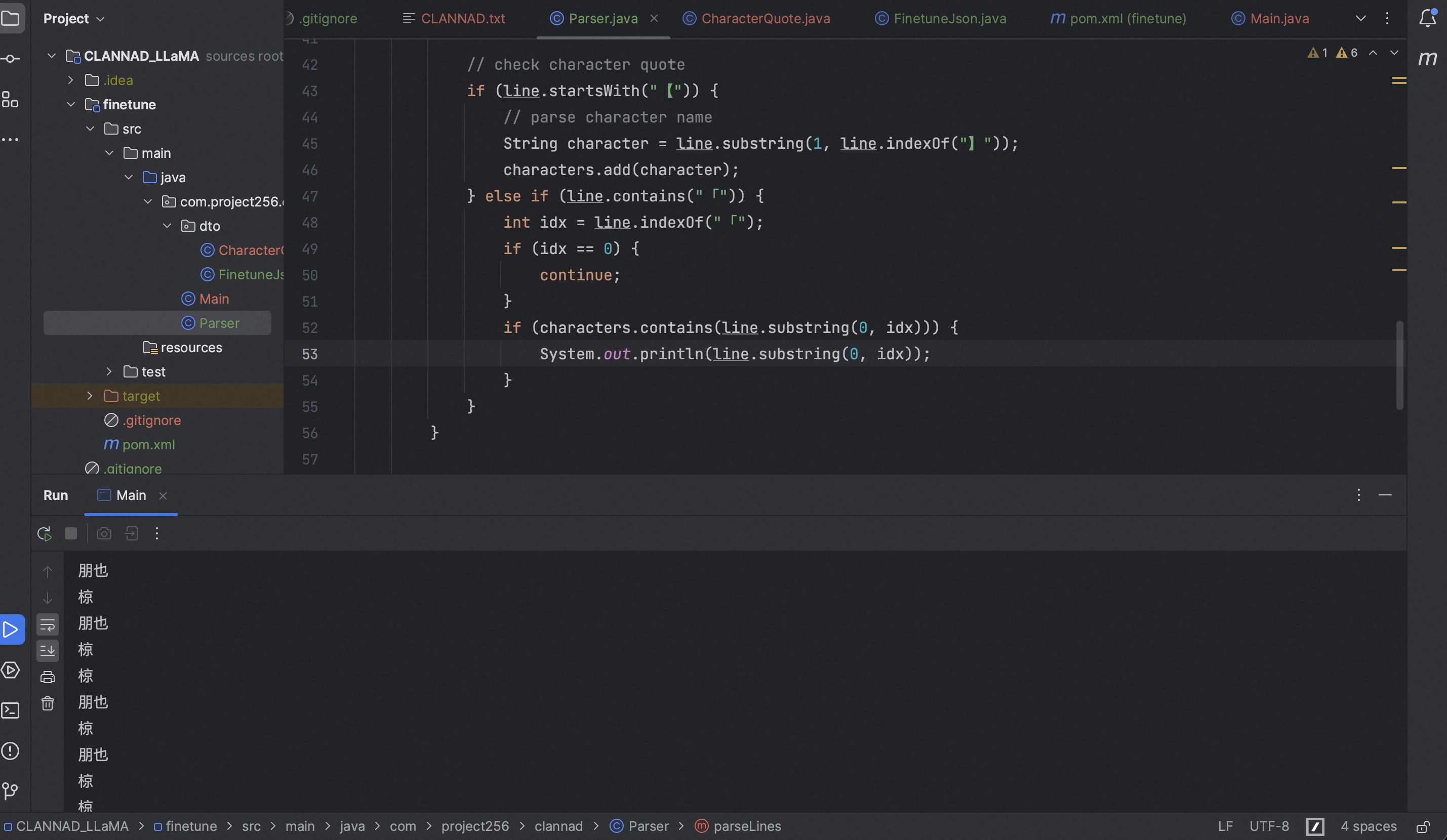
角色列表,都是老朋友真怀念啊
由于文本中,还有一些角色并没有通过“【】”圈起来,但处于单个句子的前方,因此先抽取角色名字列表,然后再做匹配,从而提升准确度。
因为文本中,被”【】“圈起来的角色文本在文件的上方,因此直接使用Set即可,不用再重新读一遍了。
解析未被中括号括起来的角色结果
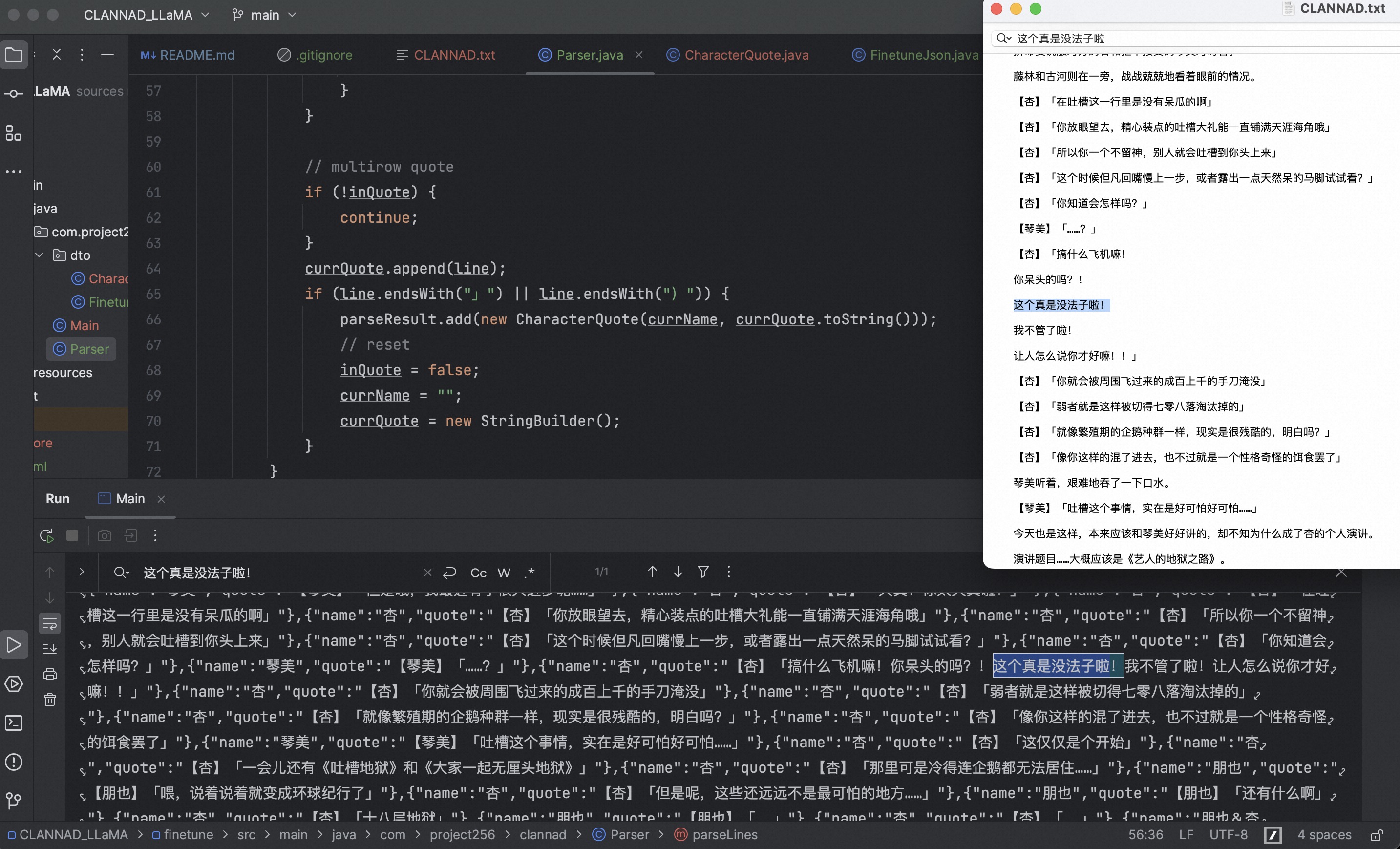
接下来使用inQuote来识别当前行是否属于某个角色的发言,外加判断行末是否是结束符号,从而是否有多行发言。
能够识别多行发言
至此Parser.java完成了,读取剧本并解析角色发言,放入对象列表中。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public class Parser private final BufferedReader reader; Parser(String file) throws FileNotFoundException { reader = new BufferedReader(new FileReader(file)); } public List<CharacterQuote> parseLines () throws IOException List<CharacterQuote> parseResult = new ArrayList<>(); Set<String> characters = new HashSet<>(); String currName = "" ; StringBuilder currQuote = new StringBuilder(); boolean inQuote = false ; String line; while ((line = reader.readLine()) != null ) { line = line.trim(); if (StringUtils.isBlank(line)) { continue ; } if (line.startsWith("【" )) { String character = line.substring(1 , line.indexOf("】" )); characters.add(character); currName = character; inQuote = true ; } else if (line.contains("「" )) { int idx = line.indexOf("「" ); if (idx == 0 ) { continue ; } if (characters.contains(line.substring(0 , idx))) { currName = line.substring(0 , idx); line = "【" + currName + "】" + line.substring(idx); System.out.println(line); inQuote = true ; } } if (!inQuote) { continue ; } currQuote.append(line); if (line.endsWith("」" ) || line.endsWith(")" )) { parseResult.add(new CharacterQuote(currName, currQuote.toString())); inQuote = false ; currName = "" ; currQuote = new StringBuilder(); } } return parseResult; } }
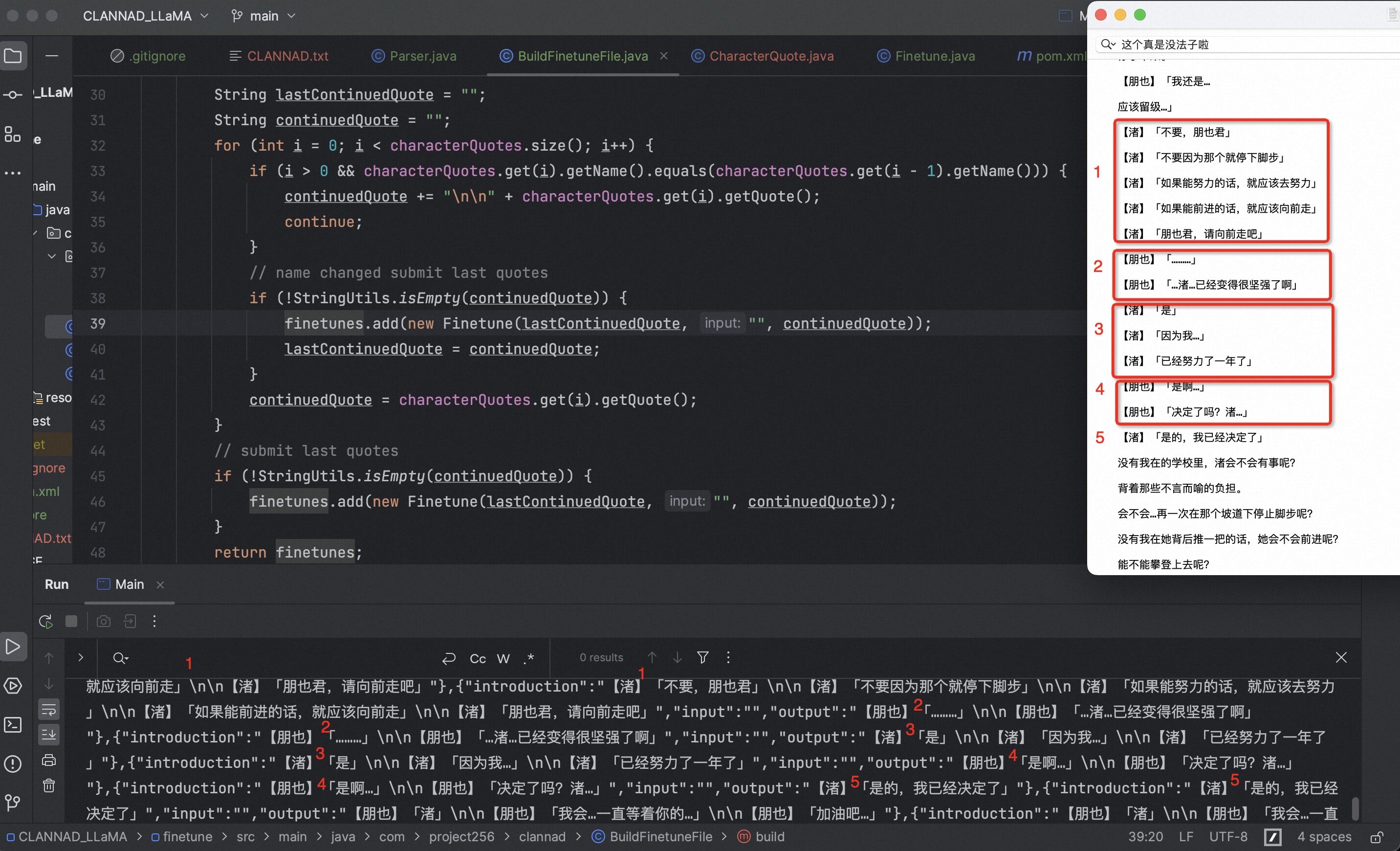
构造微调JSON 成功完成了对话的解析,接下来另开一个类用于构造微调JSON。
将上一步的角色发言处理为Finetune中的对话。
构造12、23、34式对话,保留对话上文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class BuildFinetuneFile List<CharacterQuote> characterQuotes; BuildFinetuneFile(List<CharacterQuote> quotes) { characterQuotes = quotes; } public List<Finetune> build () if (CollectionUtils.isEmpty(characterQuotes)) { return null ; } List<Finetune> finetunes = new ArrayList<>(); String lastContinuedQuote = "" ; String continuedQuote = "" ; for (int i = 0 ; i < characterQuotes.size(); i++) { if (i > 0 && characterQuotes.get(i).getName().equals(characterQuotes.get(i - 1 ).getName())) { continuedQuote += "\n\n" + characterQuotes.get(i).getQuote(); continue ; } if (!StringUtils.isEmpty(continuedQuote)) { finetunes.add(new Finetune(lastContinuedQuote, "" , continuedQuote)); lastContinuedQuote = continuedQuote; } continuedQuote = characterQuotes.get(i).getQuote(); } if (!StringUtils.isEmpty(continuedQuote)) { finetunes.add(new Finetune(lastContinuedQuote, "" , continuedQuote)); } return finetunes; } }
输出文件 直接构造个Main文件,执行一波~接下来就是微调模型了,本节结束。
1 2 3 4 5 6 7 8 public class Main public static void main (String[] args) throws IOException Parser parser = new Parser("CLANNAD.txt" ); BufferedWriter out = new BufferedWriter(new FileWriter("finetune_json/CLANNAD_LLaMA_finetune.json" )); out.write(new Gson().toJson(new BuildFinetuneFile(parser.parseLines()).build())); out.close(); } }